در این پست وبلاگ، قصد داریم روش خوشهبندی (Clustering) را با استفاده از کتابخانه Scikit-Learn در پایتون بررسی کنیم.
خوشهبندی یک روش یادگیری بدون نظارت است که در آن، اشیاء داده به دستههای مشابه تقسیم میشوند. به عبارت دیگر، هدف این است که اشیاء داده که در طول زمان جمعآوری شدهاند و هیچ برچسب ندارند، به گروههای مشابه تقسیم شوند.
ابتدا، ما برای شروع کار، کتابخانه Scikit-Learn را نصب میکنیم:
!pip install scikit-learn
حالا، یک مجموعه داده ساده برای آموزش مدل خوشهبندی بسازیم:
import numpy as np import matplotlib.pyplot as plt from sklearn.datasets import make_blobs # create a simple dataset X, y = make_blobs(n_samples=300, centers=4, cluster_std=0.60, random_state=0) plt.scatter(X[:, 0], X[:, 1], s=50) plt.show()
خروجی برنامه:
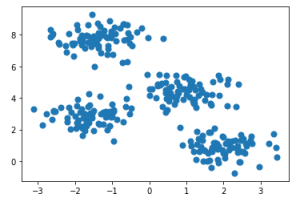
در این قطعه کد، یک مجموعه داده ساده با ۳۰۰ نمونه ایجاد شده و به صورت تصادفی با ۴ خوشه مختلف توزیع شده است. برای ساختن مدل، این دادهها به دو بخش آموزشی و تست تقسیم میشوند:
from sklearn.cluster import KMeans # create a KMeans clustering object kmeans = KMeans(n_clusters=4, init='k-means++', max_iter=300, n_init=10, random_state=0) # train the model on the dataset y_kmeans = kmeans.fit_predict(X)
حالا، با استفاده از دادههای خوشهبندیشده، میتوانیم خوشهها را رسم کنیم:
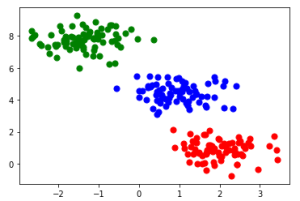
plt.scatter(X[y_kmeans == 0, 0], X[y_kmeans == 0, 1], s=50, c='red', label='Cluster 1') plt.scatter(X[y_kmeans == 1, 0], X[y_kmeans == 1, 1], s=50, c='blue', label='Cluster 2') plt.scatter(X[y_kmeans == 2, 0], X[y_kmeans == 2, 1], s=50, c='green', label='Cluster 3')
خروجی برنامه: